
О некоторых результатах первого года: исследование влияния лингвистической предобработки на интерпретируемость тематических моделей
6 мая в 18:00 состоялся первый открытый семинар в 2022 году. Участницы научно-учебной группы Евгения Колпащикова, Ася Карышева, Анна Москвина и Маргарита Кирина выступили с докладом по тематическому моделированию. Изучение этого цифрового метода было одной из главных задач прошлого «сезона». Некоторые полученные результаты были представлены на вводном семинаре.
«Тематическое моделирование художественных текстов с помощью LDA: о влиянии лингвистической предобработки на интерпретируемость моделей»
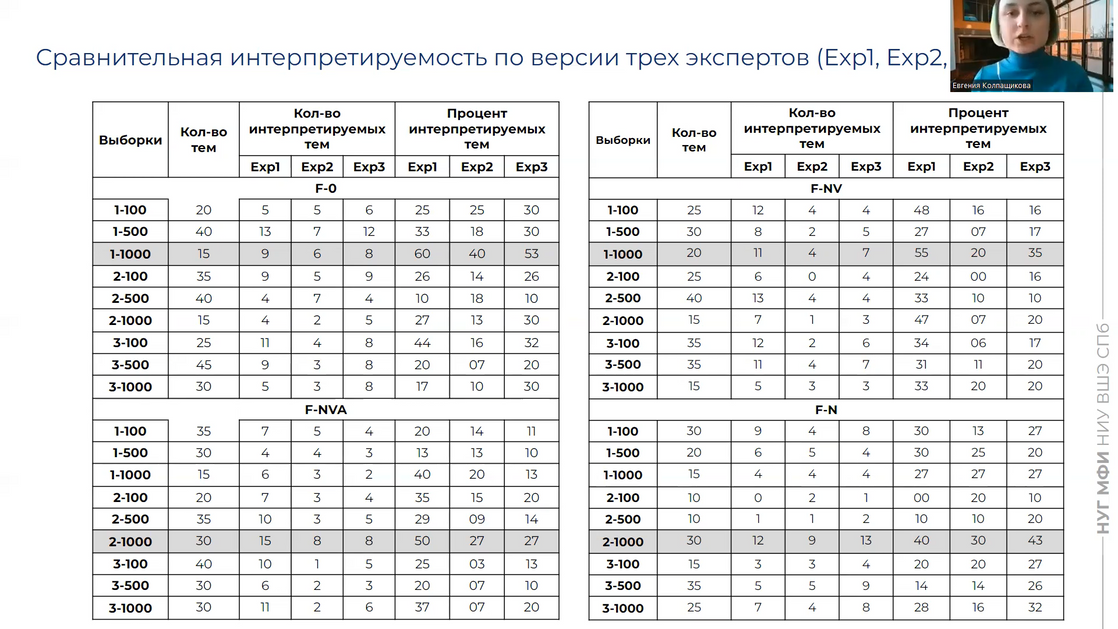
Члены научно-учебной группы рассказали о главных принципах тематического моделирования и объяснили суть метода LDA (латентного размещения Дирихле). Материалом исследования стал корпус русского рассказа первой трети ХХ века, а именно три выборки, охватывающие три важных исторических периода. Стоит отметить, что исследовательский материал был значительно расширен по сравнению с пилотными экспериментами. Для каждого периода были сформированы вложенные выборки по 100-500-1000 рассказов.

Другой важной особенностью работы стала лингвистическая подготовка данных, о которой подробно рассказали участницы: помимо токенизации и лемматизации, для текстов была представлена частеречная разметка средствами библиотеки spaCy. Исследователи варьировали частеречные фильтры: без частеречных фильтров и с частеречными фильтрами, оставляя 1) только существительные, 2) существительные и глаголы, 3) существительные, глаголы и прилагательные. Интересным выводом стало то, что наиболее точной с этой точки зрения оказалась модель без частеречных фильтров. Качество построенной модели (оптимальное количество топиков) оценивалось по критерию когерентности, которая более других коррелирует с экспертной разметкой.
{kind=link}
{kind=link}
{kind=link}
По завершении доклада состоялась оживленная дискуссия, в которой приняла участие Елена Валерьевна Маркасова, доктор филологических наук, профессор Пекинского университета. Елена Валерьевна поставила вопрос о применимости модели к темам, имплицитно присутствующим в тексте (например, к рассказу о любви, в котором нет или почти нет слов этой тематики). Важность привлечения экспертов-литературоведов для оценки результатов автоматического извлечения тем художественных произведений, в том числе для выявления подобных случаев, была особо отмечена дискуссантами.
Видеозапись встречи
Post Scriptum
Выражаем благодарность всем участникам семинара. Спасибо за интерес и оживленную дискуссию!
До скорой встречи!