
Итоги месяца. Ноябрь – междисциплинарный подход
В ноябре 2021 года на открытых семинарах НУГ выступили С. О. Шереметьева и А. Ю. Володин. В своих докладах они познакомили участников с онтологическими и просопографическими ресурсами, их особенностями и ограничениями. О комплексных способах представления неструктурированных данных читайте в этом материале.
«Онтологии как база знаний систем искусственного интеллекта. Об одном подходе к использованию онтологических ресурсов для интеллектуальной обработки неструктурированной информации»
На встречах научно-учебной группы Светлана Олеговна Шереметьева, доктор филологических наук. профессор кафедры Лингвистики и Перевода и директор научно-образовательного центра «Лингво-инновационные технологии» Южно-уральского государственного университета, представила два доклада, посвященных онтологиям – инструментам инжиниринга знаний, широко применяющимся в системах искусственного интеллекта.
Первая лекция была вводной и позволила слушателям получить представление о том, что такое онтология, какие источники получения онтологических знаний существуют и какие подходы к построению таких ресурсов выделяются. Неизбежны и проблемы, с которыми сталкивается исследователь, разрабатывая предметные онтологии. Как они решаются – С. О. Шереметьева рассказывает на примерах исследований коллег и исходя из личного опыта.
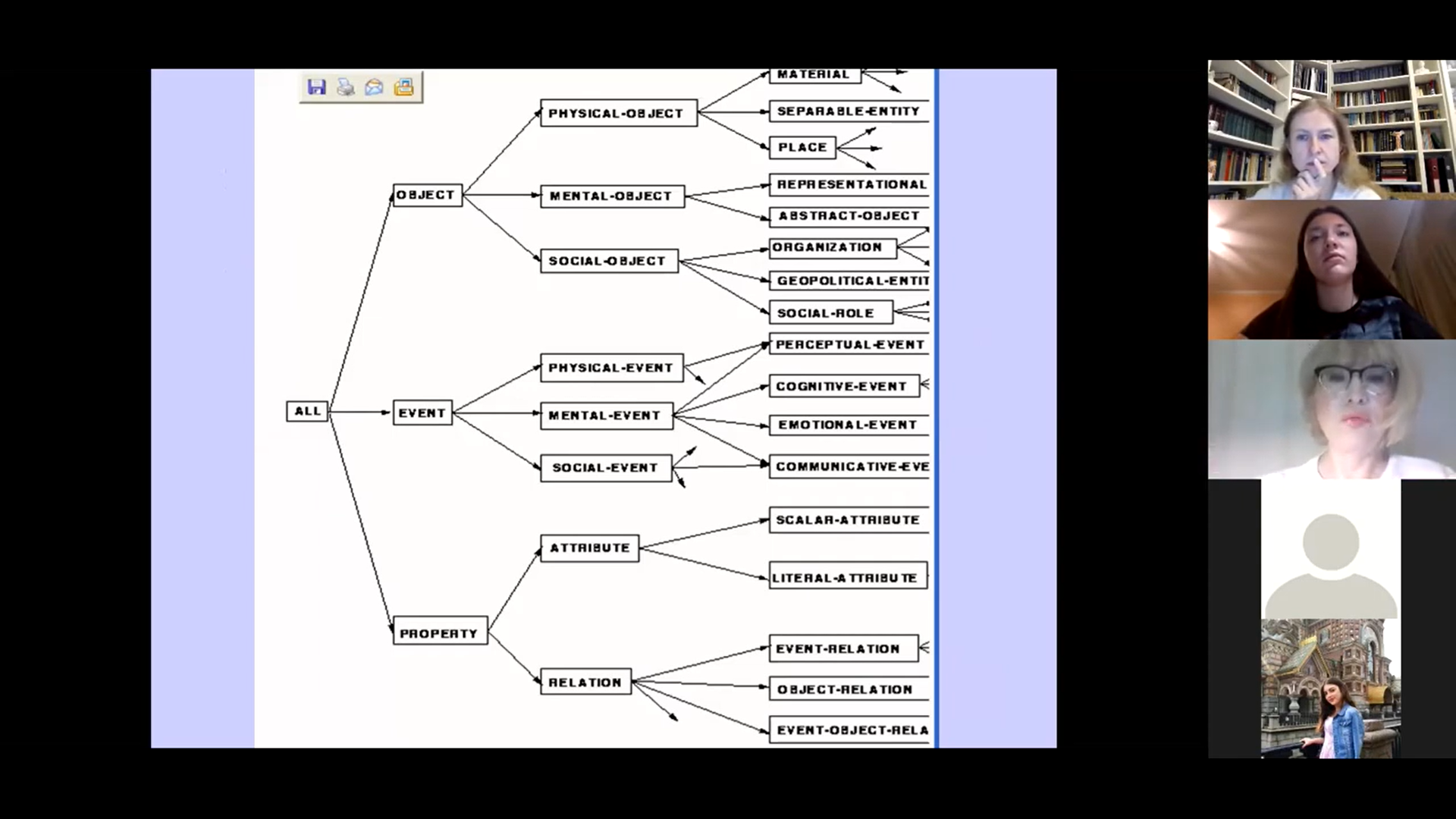
Через неделю участники семинара НУГ продолжили обсуждение «онтологического» вопроса. Интеллектуальная обработка неструктурированных текстовых данных представляет собой непростую задачу. Ее решение видится в разработке и внедрении семантических технологий для анализа. С. О. Шереметьева делится результатами работы команды научно-образовательного центра Южно-Уральского государственного университета. Так, на примерах реализованных группой проектов, посвященных созданию концептуально аннотированных ресурсов для предметной области «Терроризм» и использованию онтологических ресурсов для извлечения эмоций из русского поэтического текста, были продемонстрированы этапы построения онтологий и применявшиеся для этого программы.

Видеозаписи семинаров доступны на нашем канале YouTube по ссылкам: доклад от 12 ноября (https://www.youtube.com/watch?v=UIVaSr3uuuw&t=4s) и доклад от 19 ноября (https://www.youtube.com/watch?v=RauNEMGw-ko&t=2s).
«История с биографией: капта из исторических источников на примере биографических онлайн-проектов»
Доклад Андрея Юрьевича Володина, кандидата исторических наук, доцента кафедры исторической информатики исторического факультета МГУ и одного из ведущих специалистов в области исторической информатики (historical information science) и «цифровой истории» (digital history), был посвящен вопросам, связанным с моделированием биографии.
Мы живем в эпоху «больших данных». Но что такое данные? В литературе сравнительно давно, еще в XX-м веке, в качестве оппозиции данным, которые собраны и даны, появилось понятие капта. Капта – это данные, которые получены, или «схвачены», каким-то образом, при этом методология их сбора, порой, оказывается даже важнее содержания.

Сбор данных – фундаментальная часть исследования в гуманитарных науках, когда данные все чаще становятся не столько отправной точкой анализа, сколько его итогом. На примере биографических онлайн-проектов А. Ю. Володин демонстрирует задачи, дихотомии, а также ограничения цифровой биографики.
Публикуем видеозапись мероприятия:

Post Scriptum
Выражаем благодарность Светлане Олеговне Шереметьевой и Андрею Юрьевичу Володину, а также всем участникам семинара. Спасибо за интерес и оживленную дискуссию!
До новых встреч!