Обучение с подкреплением в Super Mario Bros. Сравнение алгоритмов DQN и Dueling DQN

О нас
Мы — Владислав и Дмитрий Артюховы, Артём Брежнев, Арсений Хлытчиев и Егор Юхневич — учимся в 10-11 классах в разных школах Краснодара. С программированием каждый из нас знаком довольно давно, мы писали олимпиады на С++. Однако почти все члены команды раньше не работали на Python, а для написания проекта в короткий пятидневный срок он был необходим. Поэтому первым испытанием для нас стало преодоление слабой типизации Python и незнакомого синтаксиса. Но обо всем по порядку.
Немного теории
На школе Питерской Вышки нам предстояло создать нейронную сеть, которая использует reinforcement learning для обучения агента играть в Super Mario Bros.
Reinforcement Learning
В основе RL алгоритмов лежит принцип взаимодействия агента и среды. Обучение происходит примерно так: агент совершает в среде действие и получает награду (в нашем случае Марио умеет прыгать и перемещаться вправо); среда переходит в следующее состояние; агент опять совершает действие и получает награду; подобное повторяется, пока агент не попадет в терминальное состояние (например, смерть в игре).
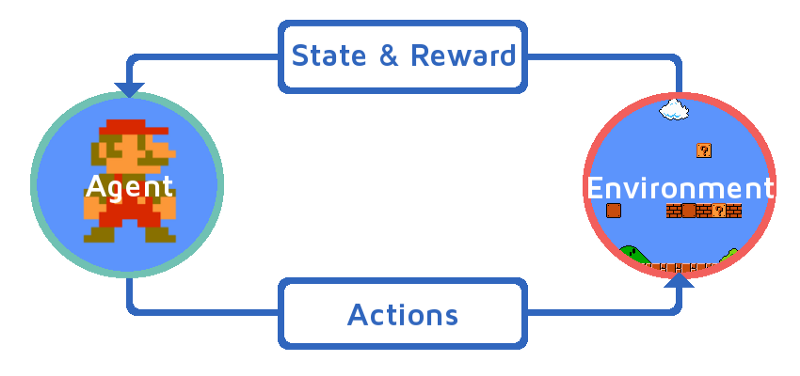
Основная цель агента заключается в максимизации суммы наград за весь эпизод — период от старта игры до терминального состояния. Особенностью обучения с подкреплением является отсутствие данных для тренировки, поэтому агент обучается на данных, которые получает, взаимодействуя со средой.
Q-learning
В основу нашей модели лег алгоритм Q-learning. Q-learning — это модель, которая обучает некоторую функцию полезности (Q-функцию). Эта функция на основании текущего состояния и конкретного действия агента вычисляет прогнозируемую награду за весь эпизод (Q-value).Агент совершает действия на основании некоторого свода правил — политики. Политика нашего агента называется Epsilon-Greedy: с некоторой вероятностью агент совершает случайное действие, иначе он совершает действие, которое соответствует максимальному значению Q-функции.