
Семинар НУГ "Реализация расчета числовых параметров сравниваемых текстов на языке программирования Python"
15 октября 2024 года состоялся двадцать восьмой семинар научно-учебной группы по исследованию частотных характеристик языка на тему «Реализация расчета числовых параметров сравниваемых текстов на языке программирования Python». С докладами выступил участник НУГ Богданов Александр Денисович. Семинар был посвящен алгоритмам обработки лингводанных для исследования роста словаря и особенностей функции роста у разных авторов. Выявление зависимости роста словаря от объёма текста может помочь понять особенности текстов, созданных искусственным интеллектом, и авторские тексты. Особенности алгоритмизации лингвостатистических задач включают первичную обработку текста и выделение словоформ (tokens).
{kind=link}
{kind=link}
{kind=link}
Обработка естественного языка (NLP) является востребованным и быстро развивающимся направлением, обусловленным широким внедрением искусственного интеллекта в повседневное общение. Существуют готовые библиотеки Python для обработки естественных языков, такие как NLTK и относительно новая SpaCy.
В рамках НУГ ставятся задачи по приобретению навыков программирования на Python. Параллельно проводятся исследования в области квантитативной лингводидактики с использованием простых программных средств, таких как Excel. Основная работа при лингвистических вычислениях связана с частотными словарями текстов, представленными в виде таблиц с порядковыми номерами слов, самими словами и частотой их вхождения в текст.
Алгоритмы чтения текстов и составления частотных словарей реализованы на встроенном в Excel языке программирования VBA. Реализованный алгоритм составления частотного словаря является однопроходным и просматривает исходный текст построчно за один проход. Текст очищается от спецсимволов, знаков препинания и цифр, однако для некоторых случаев (например, апостроф в середине слова) требуются исключения.
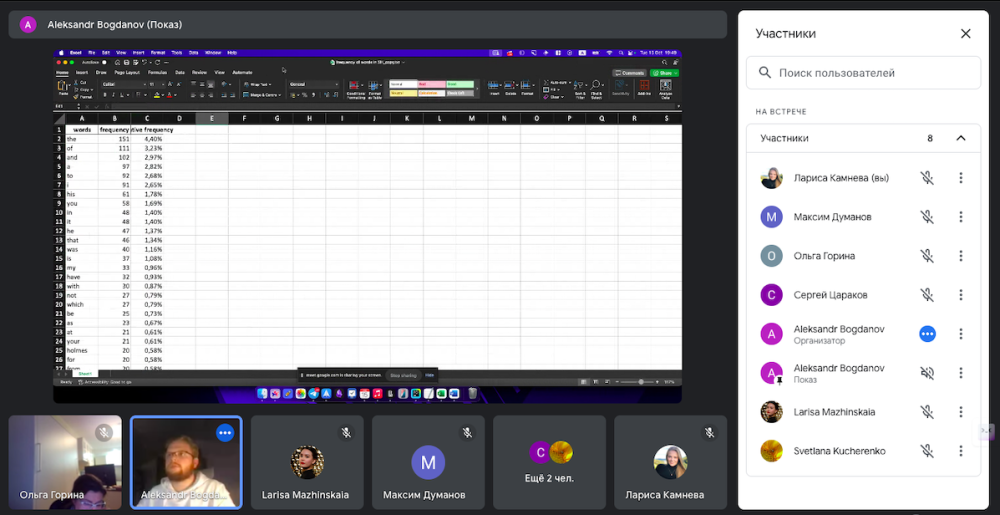
Основная работа при лингвистических вычислениях идет с частотными словарями текстов, представляющими из себя таблицы, содержащие порядковый номер слова, само слово и частоту его вхождения в текст. Эти таблицы на реальных текстах могут иметь весьма значительны размер. Для хранения и обработки таких массивов (сортировка, поиск) нам удобен Excel. Просто заменить все символы кроме литер на пробелы, или удалить их, не представляется возможным. Например, при замене апострофа в довольно часто употребляемом английском слове day’s на пробел получится два слова, одно из которых не существует. Более того, при удалении апострофа получится одно слово, но с другими грамматическими признаками. Таким образом, для апострофа, находящегося в середине слова (например, такие варианты слов как day’s, couldn’t, mystery’s и т.п.) надо сделать исключение. Отдельную проблему составляет перенос слов в конце строки на следующую строку, и определение символа, использованного в качестве переноса: тире, знак минуса, длинное тире и другие символы. При наличии символа переноса слова в конце строки, необходимо вычитать из текста следующую строку и взяв первое слово из новой строки, слить его с последним из предыдущей. Получив очередное слово из читаемого текста, алгоритм переводит все буквы слова в строчные для единообразия и передает в таблицу excel. Если такое слово в таблице уже есть, к соответствующей слову частоте добавляется единица, если такого слова нет, то слово добавляется в конец таблицы и его частоте присваивается единица. После обработки всех слов из исходного текста, частотный список упорядочивается по частоте, а для слов с одинаковой частотой, по алфавиту. По мере чтения слов из исходного текста, алгоритм вычисляет удельную лексическую плотность текста. Подсчитывается количество уникальных слов (размер словаря) на определенном объеме прочитанного текста. Как правило – это размер словаря на каждую очередную порцию из 1000 слов текста. Это очень важный параметр текста. Он позволяет наблюдать за равномерностью лексической плотности по мере увеличения размера текста и сравнивать этот показатель у различных текстов. Кроме того, по мере прочтения текста, алгоритм заносит во внутренний массив значения размера словаря, что позволяет по завершению работы вывести параметры аппроксимации зависимости размера словаря от размера текста по Хипсу . . Нас в дальнейшем будет интересовать показатель степени в этой аппроксимации. Так же представляет интерес относительная частота самого частотного слова в словаре, так называемая авторская константа.
Задача вычисления лингвистических параметров (авторская константа, удельная лексическая плотность, скорость роста словаря и тому подобные параметры) позволяет попытаться решить задачу определения авторства. С точки зрения практического применения это важная и актуальная задача (угрозы терроризма, судебные разбирательства, просто шантаж, плагиат и т.д)
На семинаре была продемонстрирована работа приложения на основании работы Артура Конан Дойла «Шерлок Холмс».
По результатам работы была получена таблица, с который вы можете ознакомиться по ссылке
Также важно отметить, что данная программа уже была использована при работе над последней статьей НУГа, и прямо сейчас участники продолжают работу над ее усовершенствованием.
Ссылка на доклад