
Презентация проекта «Текст как Big Data: моделирование конвергентных процессов в языке и речи цифровыми методами» и Лаборатории языковой конвергенции НИУ ВШЭ в СПб
16 июня состоялась очно-заочная встреча, посвященная официальной презентации проекта «Текст как Big Data: моделирование конвергентных процессов в языке и речи цифровыми методами», реализуемого вместе с московскими коллегами в результате победы в конкурсе Фундаментальных научных исследований распределенными межкампусными научными подразделениями НИУ ВШЭ. На семинаре выступили Татьяна Шерстинова, Анастасия Колмогорова, Георгий Мороз и Борис Орехов — руководители основных направлений по реализации проекта — с презентацией исследований, проводимых партнерскими подразделениями.

В начале встречи Татьяна Шерстинова, заведующий Лабораторией языковой конвергенции в Санкт-Петербурге, кратко презентовала проект «Текст как Big Data: моделирование конвергентных процессов в языке и речи цифровыми методами». Исследования, проводимые подразделением в рамках проекта, связаны с применением технологических достижений таких областей развития искусственного интеллекта, как Natural Language Processing (обработка естественного языка) и Natural Language Understanding (понимание естественного языка), к массивам текстовых данных, которые традиционно считались сферой применения качественных методов филологического и коммуникативного анализа — художественным текстам и устной повседневной речи.
{kind=link}
{kind=link}
{kind=link}
Затем каждый из руководителей отдельных направлений исследовательской работы в рамках проекта более подробно рассказал о поставленных командами задачах и об имеющемся научном заделе.
Построение ландшафта лингвистики: анализ аннотаций лингвистических статей
{kind=link}
{kind=link}
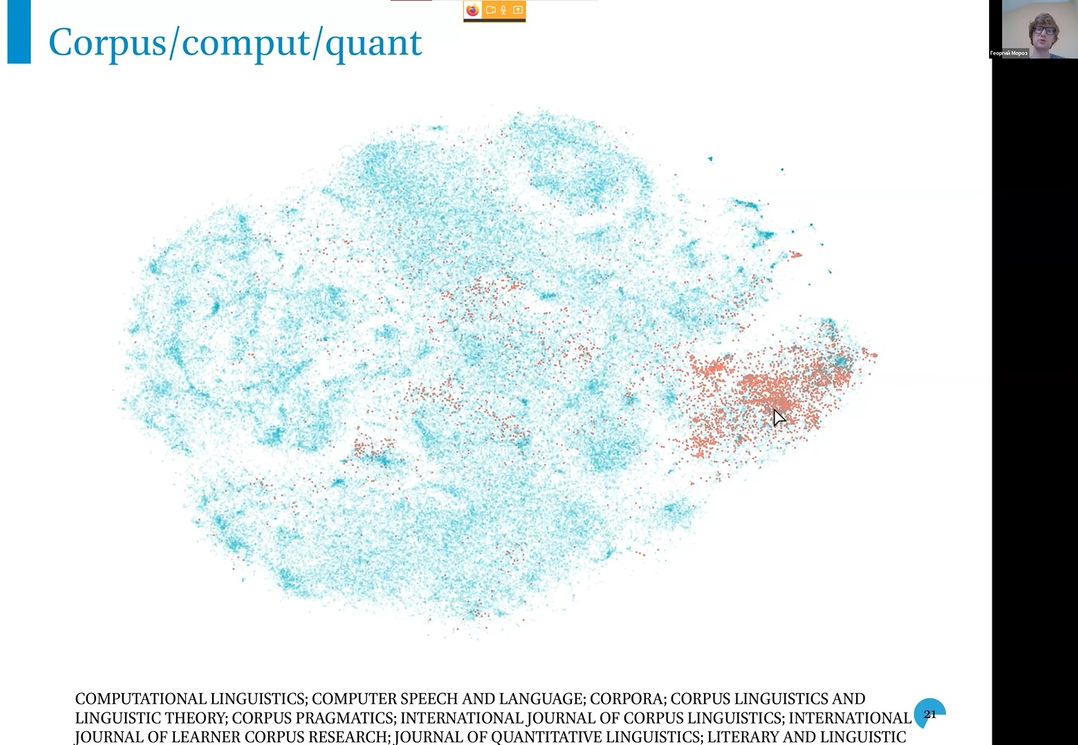
Георгий Мороз, заведующий Международной лабораторией языковой конвергенции (НИУ ВШЭ, Москва), представил проект, в рамках которого производится выгрузка и анализ аннотаций из лингвистических журналов. Круг журналов, который будет анализироваться, уже очерчен, и «выкачано» более 100 тысяч аннотаций. Есть основание надеяться, что удастся представить полученные аннотации в 2D-пространстве, которое осмысленно определит, кто есть кто в лингвистике. Такое пространство позволит анализировать междисциплинарную близость лингвистических областей, кластеризовать лингвистические журналы, исследовать публикационные практики (среднее количество авторов работ, гендерное распределение по областям лингвистики), исследовать междисциплинарность отдельных исследователей и многое другое.
О трех компьютерно-лингвистических исследованиях в пределах digital humanities

Борис Орехов, ведущий научный сотрудник Международной лаборатории языковой конвергенции, руководитель магистерской образовательной программы «Цифровые методы в гуманитарных науках», рассказал о трех компьютерно-лингвистических направлениях, в которых он видит развитие в рамках проекта. Каждое из исследований предполагает работу с культурным субстратом:
Проект «Культуромика» на базе Google N-gram Viewer
Обрабатываются данные Google N-gram Viewer для области, которая называется «культуромика», которую в своих публикациях на русском языке развивала А. А. Бонч-Осмоловская. В основе этой области лежит идея о том, что частотность слов в письменных источниках за определенный период не случайна, а соотносится с культурно значимыми событиями. Наша задача в том, чтобы с помощью статистики «отловить» выбросы в этой частотности, и таким образом создать набор модельных случаев, где культуромика для русского языка показывает значимые результаты.
Тематическое моделирование коллекции дневников «Прожито»
Ведется работа с коллекцией дневников «Прожито», целью которой является поиск с помощью тематического моделирования тенденций о том, о чем писали люди в разные периоды своей жизни и в разные эпохи истории страны.
Разработка современных языковых моделей для computational literary studies
С помощью глубокого обучения проводится работа над созданием современных языковых моделей, которые помогали бы решать задачи computational literary studies.
О трех проектах по компьютерной лингвистике
{kind=link}
{kind=link}
Анастасия Колмогорова, заместитель заведующего Лабораторией языковой конвергенции НИУ ВШЭ в СПб, академический руководитель образовательной программы «Языковые технологии в бизнесе и образовании», представила три проекта, по которым ведет работу ее команда.
«Школьникам об истории, но в разное время»
Проект с текстами учебников по истории России, изданных в разное время. Цель – проанализировать при помощи методов компьютерной обработки текстов, как меняется тональность и тематический фокус внимания при изложении одного и того же материала в текстах учебников, изданных в разные периоды развития советского/ российского общества.
«Эмоциональный анализ текстов социальных сетей»
Эмоциональная разметка текстов на русском языке: проводятся эксперименты с разными интерфейсами, моделями эмоций, способами постановки вопроса для разметчика, а также с моделями для мультимодальной разметки эмоции, манифестируемой по разным каналам (текстовому, жестовому, просодическому).
«Моделирование наиболее эффективных продающих стратегий на материале звукозаписей речи торговых представителей»
Распознавание и аннотирование коллекции записей устной речи торговых представителей, поиск речевых паттернов успешного «продажника» и разработка способов их автоматического детектирования.
О создании Корпуса русского рассказа XX века и Устного корпуса повседневной речи молодежи

Татьяна Шерстинова, заведующий Лаборатории языковой конвергенции НИУ ВШЭ в СПб, академический руководитель образовательной программы «Филология», отметила, что в Лаборатории языковой конвергенции большое внимание будет уделено построению новых лингвистических ресурсов. Прежде всего, планируется расширение Корпуса русского рассказа 1900-1930 на весь XX век, на его материале будет продолжена апробация современных компьютерных методов обработки методов машинного и глубокого обучения к литературным текстам. Другое важное направление работы — создание представительных ресурсов устной звучащей русской речи: расширение расшифрованного объема корпуса ОРД и создание нового корпуса повседневной звучащей речи - Устного корпуса современной повседневной речи молодежи («Один речевой день» версии 2023 г.), работа над которым уже началась.
Post Scriptum
Мы благодарим всех участников семинара за проявленный интерес к проекту и оживленную дискуссию!
До новых встреч!
Колмогорова Анастасия Владимировна
Лаборатория языковой конвергенции: Научный сотрудник
Мороз Георгий Алексеевич
Международная лаборатория языковой конвергенции: Заведующий лабораторией
Орехов Борис Валерьевич
Международная лаборатория языковой конвергенции: Ведущий научный сотрудник
Шерстинова Татьяна Юрьевна
Лаборатория языковой конвергенции: Заведующий лабораторией