
Большие данные и любительская литература: о количественном анализе феномена фанфикшн
7 июля в рамках проекта «Текст как big data: моделирование конвергентных процессов в языке и речи цифровыми методами» прошел очередной открытый семинар Лаборатории языковой конвергенции. С докладом «Количественный анализ феномена любительской массовой литературы на материале русскоязычной электронной базы фанфикшн» выступила Полина Максименко, стажер-исследователь Лаборатории, студентка 3 курса ОП «Филология» НИУ ВШЭ СПб.

Доклад начался с краткого введения в историю фанфикшн и его становление в качестве феномена массовой сетевой литературы. Затем Полина рассказала о фанатской культуре и распространении фан-текстов в Интернете, а также привела несколько примеров популярных специализированных ресурсов для размещения фанфикшн.
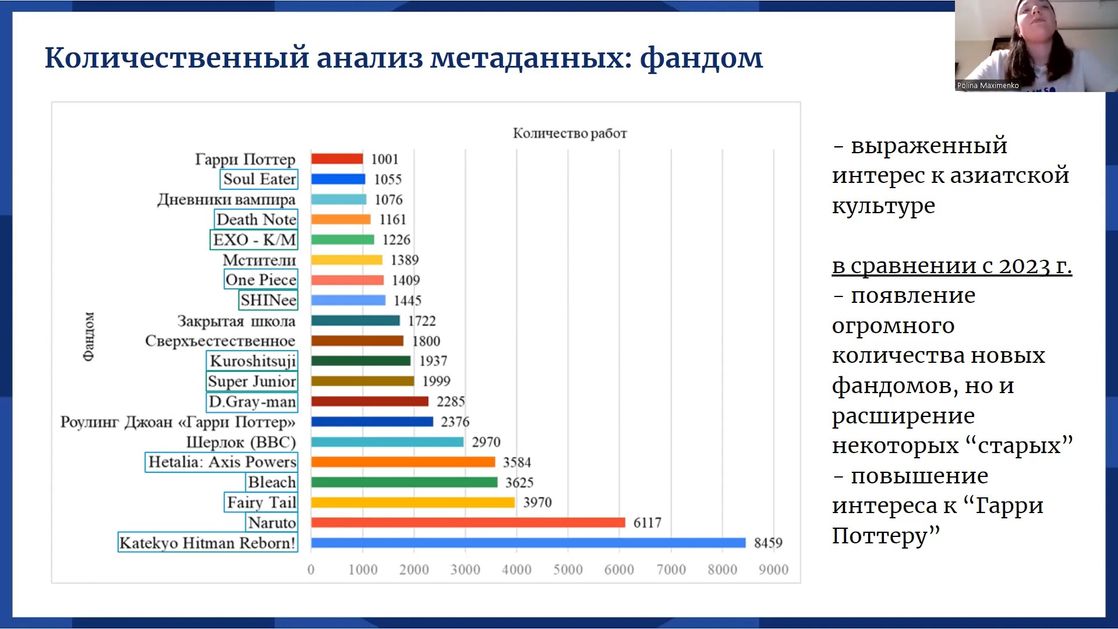
Следующая часть доклада была посвящена описанию портала «Книга Фанфиков» (ficbook.net), крупнейшей русскоязычной онлайн-площадки для публикации фанатского творчества. Были также подробно описаны многочисленные классификации фанфикшн-текстов: по направленности, возрастному рейтингу, жанру, тематике и др. Данные по описанным параметрам впоследствии вошли в полученную электронную базу наряду с текстами, размещенными на портале. Кроме того, Полина описала метод создания базы — технологию веб-скрейпинга, реализованную в виде Python-скрипта. Отметим, что созданная электронная база состоит из 136257 текстов и метаданных.
{kind=link}
{kind=link}
В последней части доклада были изложены результаты статистической обработки метаданных, включая любопытные выводы, например, о том, что фанфикшн-тексты в большинстве случаев не содержат описания эротических сцен, вопреки стереотипным суждениям. Докладчица также упомянула проведенную лингвистическую обработку текстов (токенизацию и лемматизацию), с помощью которой тексты, входящие в базу, смогут послужить материалом для дальнейшего изучения. В качестве перспектив исследований были выделены расширение электронной базы, изучение отдельных фанатских сообществ и применение методов искусственного интеллекта.
В завершение семинара состоялось обсуждение использования полученных данных для обучения моделей машинного обучения, в частности — для решения задачи классификации текстов по тематическим меткам.
Post Scriptum
Мы благодарим Полину Максименко за увлекательный доклад, а всех наших слушателей — за проявленный интерес к проекту и оживленную дискуссию!
До новых встреч!
Максименко Полина Игоревна
Лаборатория языковой конвергенции: Стажер-исследователь